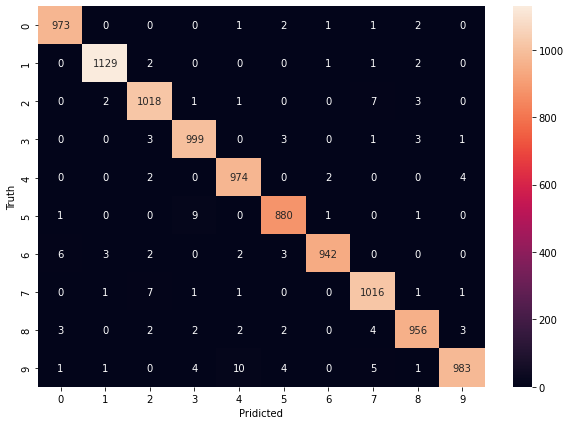
The project tries to detect handwritten digits using the MNIST dataset. The aim of this project is to implement a classification algorithm to recognize the handwritten digits using neural networks, Keras and TensorFlow. We have used Deep Neural Network (DNN) and Convolutional Neural Network (CNN) with different loss functions as well as different optimization methods. After that, we compared the results and then selected the best classification model for this dataset. Using the adam optimizer and sparse categorical cross-entropy loss function the training data accuracy of DNN was 99.87% with epoch size 30 which was the highest among the optimizers. In this case, test data accuracy was 97.42%. On the other hand, CNN gave 99.99% training accuracy using adamax optimizer and sparse categorical cross-entropy loss function with epoch size 30 and test data accuracy was 98.74% which was the best performing model for the MNIST dataset.
Dataset Details
The MNIST dataset is an acronym that stands for the Modified National Institute of Standards and Technology dataset. It is a dataset of 60,000 small square 28×28 pixel grayscale images of handwritten single digits between 0 and 9.
The task is to classify a given image of a handwritten digit into one of 10 classes representing integer values from 0 to 9, inclusively. After that, we have to use DNN and CNN with different loss functions as well as different optimization methods. Then comparing the results select the best classification model for this dataset.

Environment Requirements
The total project was done in the google colab platform for a great computation speed and quick compilation. Python 3 was chosen as a programming language because of having some additional upgrades over python2. Necessary packages were imported first and the algorithm was created which is done by installing the new packages online in python3. Apart from that it used Tensorflow version 2.8.2 , numpy==1.16.5, matplotlib==3.3.1 and Keras.
DNN Classification
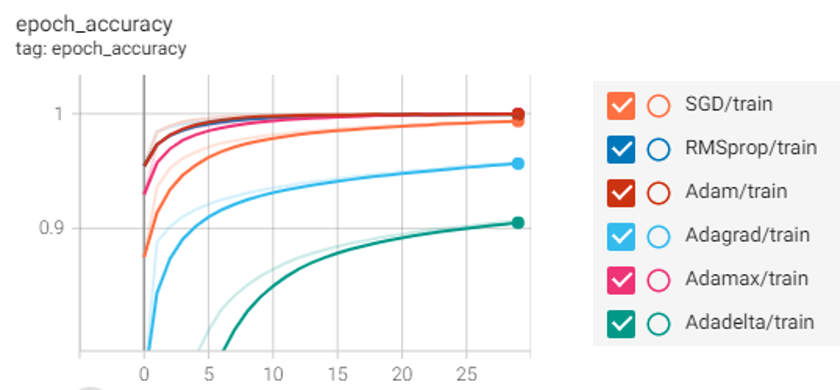
The MNIST data was split between 60,000 training images and 10,000 test images. Then training and test data were scaled for best performance. Both data were reshaped to be flattened and implemented on the input layer. Input shape was 784 and there was a hidden layer with 100 neurons where used default activation function “relu”. In the output layer, there were 10 neurons with the activation function “sigmoid” because we want to predict the probability existing only between the range of 0 and 1, sigmoid is the right choice. After that firstly we used different optimizers and loss functions to compile the model. The model was executed with 30 epochs and the output is visualized below.
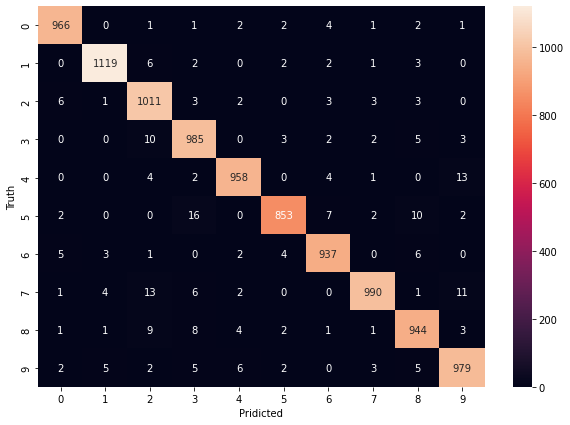
CNN Classification
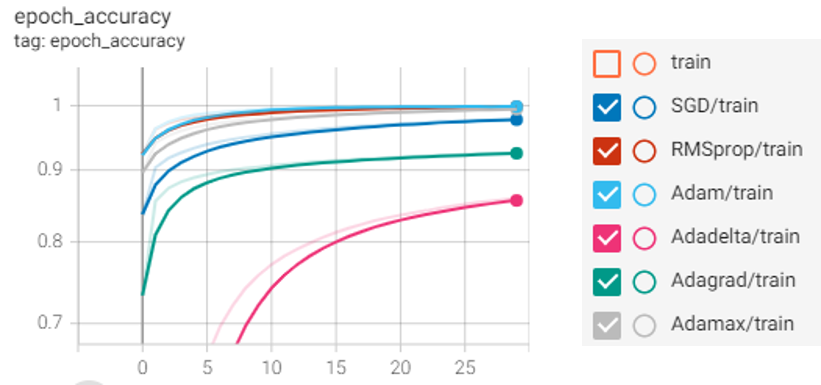
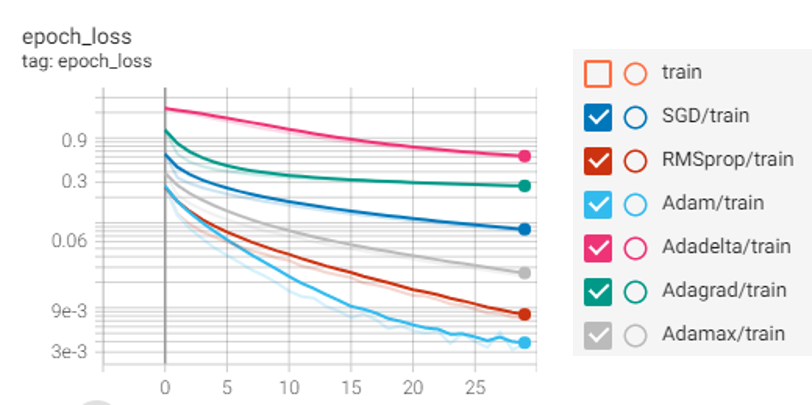
The MNIST data was split between 60,000 training images and 10,000 test images. Then training and test data were scaled for best performance. After that, the convolutional layer with the default activation function “relu” was used with the input shape (28,28,1). Then Mas Pooling layer was implemented. Both data were reshaped to be flattened and implemented on the input layer. Input shape was 784 and there was a hidden layer with 100 neurons where used default activation function “relu”. In the output layer, there were 10 neurons with the activation function “sigmoid” because we want to predict the probability existing only between the range of 0 and 1, sigmoid is the right choice. To compile the model we used different optimizers and loss functions with epoch size 30. We got adamax optimizer giving the highest accuracy and lowest loss on both training & test data with sparse categorical cross-entropy. The output is visualized below.